Monday, December 6, 2010
Error writing on System.sys at WarpPLS 1.0 start
(Note: This post refers to version 1.0 of WarpPLS only. The System.sys file has been renamed System.wrp in version 2.0 to avoid this problem.)
Some users may receive an error message on the WarpPLS command prompt window indicating that the System.sys file cannot be updated. This issue occurs when WarpPLS is launched, and seems to happen with a few Windows 7 users.
Even with this error, WarpPLS runs normally on the trial version. However, it does not allow a user to update the license information.
To solve this problem on Windows 7, follow the steps below. Similar steps related to granting users full control over a file should be followed with other Windows operating systems.
1) Go to the folder containing the WarpPLS program. Typically this will be:
C:\Program Files\WarpPLS 1.0
2) Right-click on the file System.sys, and then choose properties.
3) Click on the Security tab.
4) Click on the Users group, and then on the button to change permissions.
5) Check the option to give the group Users full control on the System.sys file.
This problem occurs because Windows 7 does not seem to grant all computer administrator rights to new users, even when those users are included in the Administrators group.
By following the instructions on this post, you will essentially be allowing any user to change the System.sys file while running WarpPLS. This should not be a problem, as long as no user decides to manually delete the System.sys file.
Wednesday, November 24, 2010
Using WarpPLS in e-collaboration studies: An overview of five main analysis steps
A new article discussing WarpPLS is available. The article is titled “Using WarpPLS in e-collaboration studies: An overview of five main analysis steps”. It has been recently published in the International Journal of e-Collaboration. A full text version of the article is available as a PDF file. Below is the abstract of the article.
Most relationships between variables describing natural and behavioral phenomena seem to be nonlinear, with U-curve and S-curve relationships being particularly common. Yet, structural equation modeling software tools do not typically estimate coefficients of association taking nonlinear relationships between latent variables into consideration. This can lead to misleading results, particularly in multivariate and complex phenomena such as those related to e-collaboration. One notable exception is WarpPLS (available from: warppls.com), a new structural equation modeling software currently available in its first release, version 1.0. The discussion presented here contributes to the literature on e-collaboration research methods by providing a description of the main features of WarpPLS, in the context of an e-collaboration study. The focus of this discussion is on the software’s features and their use, and not on the e-collaboration study itself. Particular emphasis is placed on the five steps through which a structural equation modeling analysis is conducted through WarpPLS.
Sunday, September 26, 2010
Incompatibility between WarpPLS and XLSTAT
Most users seem to have no problems installing and running WarpPLS. A minority have problems with the MATLAB Compiler Runtime, which can be addressed by following the instructions on this post.
A very small number of users seem to be unable to properly install and run WarpPLS, even after following the instructions above. A common, but not exclusive, error message in this case is: “An application has made an attempt load the C runtime library incorrectly”.
One common characteristic among these users is that they have the software XLSTAT installed on their computers. I have already received a few reports suggesting XLSTAT changes operating system settings in such a way as to prevent WarpPLS from properly running.
When those users removed XLSTAT from their computers, they were able to run WarpPLS without problems.
A very small number of users seem to be unable to properly install and run WarpPLS, even after following the instructions above. A common, but not exclusive, error message in this case is: “An application has made an attempt load the C runtime library incorrectly”.
One common characteristic among these users is that they have the software XLSTAT installed on their computers. I have already received a few reports suggesting XLSTAT changes operating system settings in such a way as to prevent WarpPLS from properly running.
When those users removed XLSTAT from their computers, they were able to run WarpPLS without problems.
Wednesday, September 15, 2010
There is no need for two-way arrows in WarpPLS
In covariance-based structural equation modeling (SEM) software tools, often one has to explicitly model correlations between predictor latent variables (LVs) to obtain related estimates. In WarpPLS, correlations between predictor LVs are automatically taken into consideration in the calculation of path coefficients.
It should be noted that when we say "two-way arrows" we are not referring to reciprocal relationships. Reciprocal relationships are usually represented via two straight arrows, each arrow pointing in a different direction. What we call "two-way arrows" here are representations of correlations.
The path coefficients calculated by WarpPLS are true standardized partial regression coefficients, of the same type as those calculated through multiple regression analysis. The difference is, of course, that in WarpPLS the model variables are LVs, which are usually measured through more than one indicator. With multiple regression, only one measure (or indicator) is used for each variable in the model.
Monday, July 26, 2010
Testing the significance of mediating effects with WarpPLS using the Baron & Kenny approach
This post discusses how you can use WarpPLS to test a mediating effect using what is often referred to as the classic Baron and Kenny approach (for a recent discussion, see: Kock, 2014). You can also test mediating effects directly with WarpPLS, using indirect and total effect outputs:
http://warppls.blogspot.com/2013/04/testing-mediating-effects-directly-with.html
Using WarpPLS, one can test the significance of a mediating effect of a variable M, which is hypothesized to mediate the relationship between two other variables X and Y, by using Baron & Kenny’s (1986) criteria. The procedure is outlined below. It can be easily adapted to test multiple mediating effects, and more complex mediating effects (e.g., with multiple mediators). Please note that we are not referring to moderating effects here; these can be tested directly with WarpPLS, by adding moderating links to a model.
First two models must be built. The first model should have X pointing at Y, without M being included in the model. (You can have the variable in the WarpPLS model, but there should be no links from or to it.) The second model should have X pointing at Y, X pointing at M, and M pointing at Y. This is a “triangle”-looking model. A WarpPLS analysis must be conducted with both models, which may be saved in two different project files; this analysis may use linear or nonlinear analysis algorithms. The mediating effect will be significant if the three following criteria are met:
- In the first model, the path between X and Y is significant (e.g., P < 0.05, if this is the significance level used).
- In the second model, the path between X and M is significant.
- In the second model, the path between M and Y is significant.
Note that, in the second model, the path between M and Y controls for the effect of X. That is the way it should be. Also note that the effect of X on Y in the second model is irrelevant for this mediation significance test. Nevertheless, if the effect of X on Y in the second model is insignificant (i.e., indistinguishable from zero, statistically speaking), one can say that the case is one of “perfect” mediation. On the other hand, if the effect of X on Y in the second model is significant, one can say that the case is one of “partial” mediation. This of course assumes that the three criteria are met.
Generally, the lower the direct effect of X on Y in the second model, the more “perfect” the mediation is, if the three criteria for mediating effect significance are met.
References
Baron, R. M., & Kenny, D. A. (1986). The moderator–mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality & Social Psychology, 51(6), 1173-1182.
Kock, N. (2014). Advanced mediating effects tests, multi-group analyses, and measurement model assessments in PLS-based SEM. International Journal of e-Collaboration, 10(1), 1-13.
Friday, July 23, 2010
Use formative latent variables with caution
One should use formative latent variables (LVs) with caution in structural equation modeling analyses using WarpPLS. It is not uncommon to see formative LVs being created simply by casually aggregating indicators, without much concern about the indicators being actually facets of the same construct. See this post for more details.
It is also important to stress that formative LVs are better assessed when included as part of a model. This is preferable to analyzing formative LVs individually; that is, as “models” that include one single LV. The loadings and cross-loadings table takes into consideration both formative and reflective LVs in its calculation, and may suggest that some indicators do not “belong” to a formative LV.
Also, certain model parameters may become unstable due to collinearity. High collinearity among indicators is to be expected in reflective LV measurement, but not in formative LV measurement. In the context of formative LV assessment, collinearity may be reflected in unstable weights, where unexpected P values (usually statistically non-significant) are associated with weights.
In formative LVs, indicators are expected to measure different facets of the LV, not the same thing. If two (or more) indicators are collinear in a formative LV, it may be a good idea to collapse them into one indicator. This can be done by defining second order LVs (a two-step, somewhat complex procedure), averaging the indicators, or simply eliminating one of the indicators from the analysis.
Thursday, July 22, 2010
Using WarpPLS in an exploratory path analysis of health-related data
There has been quite a lot of debate lately on the findings of a study known as the China Study. One of the key hypotheses of that study is that animal protein consumption (e.g., meat, dairy) causes various types of cancer, including colorectal cancer. Total cholesterol has been proposed as one of the intervening variables in connection with this effect. Given that, I decided to take a look at some of the data from the China Study and do a couple of multivariate data analysis on it using WarpPLS.
First I built a model that explores relationships with the goal of testing the assumption that the consumption of animal protein causes colorectal cancer, via an intermediate effect on total cholesterol. I built the model with various hypothesized associations to explore several relationships simultaneously, including some commonsense ones. Including commonsense relationships is usually a good idea in exploratory multivariate analyses.
The model is shown on the graph below, with the results. (Click on it to enlarge. Use the "CRTL" and "+" keys to zoom in, and CRTL" and "-" to zoom out.) The arrows explore causative associations between variables. The variables are shown within ovals. The meaning of each variable is the following: aprotein = animal protein consumption; pprotein = plant protein consumption; cholest = total cholesterol; crcancer = colorectal cancer.

The “(R)1i” below the variable names simply means that each of the variables is measured through a single indicator. This characterizes this analysis as a path analysis, rather than a true structural equation modeling (SEM) analysis. The P values were calculated through jackknifing. Like bootstrapping and other nonparametric resampling techniques, jackknifing does not require the assumption that the data be normally distributed. This is good, because I checked the data, and it does not look like it is normally distributed. So what does the model above tell us? It tells us that:
- As animal protein consumption increases, colorectal cancer decreases, but not in a statistically significant way (beta=-0.13; P=0.11).
- As animal protein consumption increases, plant protein consumption decreases significantly (beta=-0.19; P<0.01).
- As plant protein consumption increases, colorectal cancer increases significantly (beta=0.30; P=0.03). This is statistically significant because the P is lower than 0.05.
- As animal protein consumption increases, total cholesterol increases significantly (beta=0.20; P<0.01).
- As plant protein consumption increases, total cholesterol decreases significantly (beta=-0.23; P=0.02).
- As total cholesterol increases, colorectal cancer increases significantly (beta=0.45; P<0.01). Big surprise here!
Why the big surprise with the apparently strong relationship between total cholesterol and colorectal cancer? The reason is that it does not make sense, because animal protein consumption seems to increase total cholesterol, and yet animal protein consumption seems to decrease colorectal cancer.
When something like this happens in a multivariate analysis, it may be due to the model not incorporating a variable that has important relationships with the other variables. In other words, the model is incomplete, hence the nonsensical results. Relationships among variables that are implied by coefficients of association must also make sense to be credible.
Now, it has been pointed out that the missing variable here possibly is schistosomiasis infection. The dataset from the China Study included that variable, even though there were some missing values (about 28 percent of the data for that variable was missing), so I added it to the model in a way that seems to make sense. The new model is shown on the graph below. In the model, schisto = schistosomiasis infection.

So what does this new, and more complete, model tell us? It tells us some of the things that the previous model told us, but a few new things, which make a lot more sense. Note that this model fits the data much better than the previous one, particularly regarding the overall effect on colorectal cancer, which is indicated by the high R-squared value for that variable (R-squared=0.73). Most notably, this new model tells us that:
- As schistosomiasis infection increases, colorectal cancer increases significantly (beta=0.83; P<0.01). This is a MUCH STRONGER relationship than the previous one between total cholesterol and colorectal cancer; even though some data on schistosomiasis infection for a few counties is missing (the relationship might have been even stronger with a complete dataset). And this strong relationship makes sense, because schistosomiasis infection is indeed associated with increased cancer rates. More information on schistosomiasis infections can be found here.
- Schistosomiasis infection has no significant relationship with these variables: animal protein consumption, plant protein consumption, or total cholesterol. This makes sense, as the infection is caused by a worm that is not normally present in plant or animal food, and the infection itself is not specifically associated with abnormalities that would lead one to expect major increases in total cholesterol.
- Total cholesterol has no significant relationship with colorectal cancer (beta=0.24; P=0.11). The beta here is nontrivial, but too low to be significant; i.e., we cannot discard chance within the context of this relatively small dataset.
- Animal protein consumption has no significant relationship with colorectal cancer. The beta here is very low, and negative (beta=-0.03).
- Plant protein consumption has no significant relationship with colorectal cancer. The beta for this association is positive and nontrivial (beta=0.15), but the P value is too high (P=0.20) for us to discard chance within the context of this dataset.
Below is the plot showing the relationship between schistosomiasis infection and colorectal cancer. The values are standardized, which means that the zero on the horizontal axis is the mean of the schistosomiasis infection numbers in the dataset. The shape of the plot is the same as the one with the unstandardized data. As you can see, the data points are very close to a line, which suggests a very strong linear association.

In summary, an exploratory path analysis with WarpPLS can shed light on data patterns that would look rather “mysterious” otherwise. Still, one has to use commonsense, good theory, and past empirical results to derive conclusions.
Tuesday, July 13, 2010
Using WarpPLS for multiple regression analyses
There are two main advantages of using WarpPLS to conduct a multiple regression analysis. The advantages are over a traditional multiple regression analysis, where the independent and dependent variables are measured through single indicators. With WarpPLS, this would be implemented through the creation of "latent" variables that would each be associated with a single indicator; which means that they would not be true latent variables in the sense normally assumed in structural equation modeling.
The first advantage is that the calculation of P values with WarpPLS is based on nonparametric algorithms, resampling or "stable" algorithms, and thus does not require that the variables be normally distributed. A traditional multiple regression analysis, on the other hand, requires that the variables be normally distributed. In this sense, WarpPLS can be seen as conducting a robust, or nonparametric, multiple regression analysis. This first advantage assumes that all one is doing is a plain linear analysis with WarpPLS, for which one would typically use the algorithm Robust Path Analysis. See the software's User Manual for more details.
The second advantage is that WarpPLS allows for nonlinear relationships between the independent and dependent variables to be explicitly modeled. This provides a much richer view of the associations between variables, and sometimes leads to path coefficients that are different from (often higher than) those obtained through a linear analysis (as in a traditional multiple regression analysis). The nonlinear analysis algorithms available are Warp3 and variants, which yield S curves; and Warp2 and variants, which yield U curves. Again, see the software's User Manual for more details.
Sunday, June 20, 2010
Second order latent variables in WarpPLS: YouTube videos by Jaime León
The blog post below refers to a procedure employed with earlier versions of WarpPLS. For a more recent, and less time-consuming, approach see the video linked immediately below. The video shows how to create and use second (and higher) order latent variables with WarpPLS.
http://youtu.be/bkO6YoRK8Zg
***
The YouTube videos below have been created by WarpPLS user and blog commenter Jaime León. They illustrate how steps 1 and 2, described in this post, can be implemented in WarpPLS. The goal of those steps is to use second order latent variables (LVs) in an SEM analysis. Latent variable (LV) scores are generated, saved, and then used in a subsequent SEM analysis.
Step 1: YouTube video 1.
Step 2: YouTube video 2.
In the first video Jaime includes only LVs in the model, without any links among them, and then runs the SEM analysis. This generates the LV scores for the LVs, which Jaime then saves into a .txt file. The LV scores generated are then combined with indicators from the original dataset.
Note that Jaime does not set the LVs in the first video as formative before generating the scores. That is okay if the LVs are reflective; that is, if the indicators of the LVs are highly correlated. (In reflective LVs the loadings are expected to be all high, ideally greater than .7, and significant.) If not, then the LVs should be set as formative.
Also, note that Jaime combined the LV scores in standardized format with indicator data from the original dataset, which were not standardized. That is fine because WarpPLS always standardizes the raw data before proceeding to an SEM analysis. Standardized data, when used as input, will not be affected by standardization (since they are already standardized).
In the second video Jaime creates a model with new LVs, some of which include the previously generated LV scores as indicators. These are frequently referred to as second order LVs. (Although sometimes the original LVs, shown in the first video, are the ones called second order LVs.) Jaime then builds a model by creating several direct links among the LVs.
Cool example, with a Bob Marley song in the background; thanks Jaime!
Thursday, June 17, 2010
Multi-group analysis with WarpPLS: Comparing means of two or more groups
Comparing means of two groups is something that behavioral researchers often do. In fact, this is the most widely used quantitative analysis approach. This is also a form of multi-group analysis, where the number of groups is two. Common tests for comparing means are the t and and one-way ANOVA tests.
There is an arguably much better way of doing comparison of means test, with WarpPLS. Follow the steps below. This is a two-group test. Multi-group tests can be done in a similar way, through multiple two-group tests where conditions (i.e., groups) are compared pair by pair.
- Create a dummy variable (G) with numbers associated with each of the two groups - e.g., 0 for one group, and 1 for the other group. This dummy variable should be implemented as a LV with 1 indicator.
- Define your dependent (or criterion) construct (T) as you would normally do; in this case, I think that would be as a reflective LV with 3 indicators.
- Create a link between G and T, with G pointing at T.
- Estimate the model parameters with WarpPLS; this will calculate the beta and P values for the link. The P value is analogous to the P value you would obtain with a t test.
The following article goes into some detail about this procedure, contrasting it with other approaches:
Kock, N. (2013). Using WarpPLS in e-collaboration studies: What if I have only one group and one condition? International Journal of e-Collaboration, 9(3), 1-12.
This type of WarpPLS test has a number of advantages over a standard t test or a one-way ANOVA test (which are essentially the same thing). For example, it allows for the use of LVs as dependent variables; and it is a robust test, which does not require that the dependent variables be normally distributed.
Multi-group tests, with more than two groups, can also be conducted by assigning different values to each of the groups. The key here is to decide what values to assign to each group. This choice is often somewhat arbitrary in exploratory analyses. The “Save grouped descriptive statistics into a tab-delimited .txt file” option may be helpful in this respect. This is a special option that allows you to save descriptive statistics (means and standard deviations) organized by groups defined based on certain parameters. For more details, see the user manual for WarpPLS, which is available from Warppls.com.
Starting in version 6.0 of WarpPLS, the menu options “Explore multi-group analyses” and “Explore measurement invariance” allow you to conduct analyses where the data is segmented in various groups, all possible combinations of pairs of groups are generated, and each pair of groups is compared. In multi-group analyses normally path coefficients are compared, whereas in measurement invariance assessment the foci of comparison are loadings and/or weights. The grouping variables can be unstandardized indicators, standardized indicators, and labels. These types of analyzes can now also be conducted via the new menu option “Explore full latent growth”, which presents several advantages (as discussed in the WarpPLS User Manual).
Related YouTube videos:
Explore Multi-Group Analyses in WarpPLS
Explore Measurement Invariance in WarpPLS
Tuesday, June 15, 2010
Using second order latent variables in WarpPLS
The blog post below refers to a procedure employed with earlier versions of WarpPLS. For a more recent, and less time-consuming, approach see the video linked immediately below. The video shows how to create and use second (and higher) order latent variables with WarpPLS.
http://youtu.be/bkO6YoRK8Zg
***
Second order latent variables (LVs) can be implemented in WarpPLS 1.0 through two steps. These steps are referred to as Step 1 and Step 2 in the paragraphs below. Higher order LVs can also be implemented, following a similar procedure, but with additional steps.
With second order LVs, a set of LV scores are used as indicators of a LV. Often second order LVs are decompositions of a formative LV into a few reflective LVs. The scores of the component reflective LVs are used as indicators of the original formative LV.
In Step 1, you will create models that relate LVs to their indicators. Only the LVs and their indicators should be included. No links between LVs should be created. This will allow you to calculate the LV scores for the LVs, based on the indicators. You will then save the LV scores using the option “Save factor scores into a tab-delimited .txt file”, available from the “Save” option of the “View and save results” window menu.
In Step 2, you will create a new model where the saved LV scores are indicators of a new LV. This LV is usually called the second order LV, although sometimes the indicators (component LVs) are referred to as second order LVs. The rest of the data will be the same. Note that you will have to create and read the raw data used in the SEM analysis again, for this second step.
Tuesday, May 18, 2010
Selecting among different WarpPLS analysis algorithms
The blog post below refers to some algorithm features available in earlier versions of WarpPLS. For a more recent discussion on the algorithms offered, please see the latest version of the WarpPLS User Manual (link below).
http://www.scriptwarp.com/warppls/#User_Manual
***
First a quick recap of some issues already discussed in previous posts. WarpPLS offers the following analysis algorithms: Warp3 PLS Regression, Warp2 PLS Regression, PLS Regression, and Robust Path Analysis.
Many relationships in nature, including relationships involving behavioral variables, are nonlinear and follow a pattern known as U-curve (or inverted U-curve). In this pattern a variable affects another in a way that leads to a maximum or minimum value, where the effect is either maximized or minimized, respectively. This type of relationship is also referred to as a J-curve pattern; a term that is more commonly used in economics and the health sciences.
The Warp2 PLS Regression algorithm tries to identify a U-curve relationship between latent variables, and, if that relationship exists, the algorithm transforms (or “warps”) the scores of the predictor latent variables so as to better reflect the U-curve relationship in the estimated path coefficients in the model. The Warp3 PLS Regression algorithm, the default algorithm used by the software, tries to identify a relationship defined by a function whose first derivative is a U-curve. This type of relationship follows a pattern that is more similar to an S-curve (or a somewhat distorted S-curve), and can be seen as a combination of two connected U-curves, one of which is inverted.
The PLS Regression algorithm does not perform any warping of relationships. It is essentially a standard PLS regression algorithm, whereby indicators’ weights, loadings and factor scores (a.k.a. latent variable scores) are calculated based on a least squares minimization sub-algorithm, after which path coefficients are estimated using a robust path analysis algorithm. A key criterion for the calculation of the weights, observed in virtually all PLS-based algorithms, is that the regression equation expressing the relationship between the indicators and the factor scores has an error term that equals zero. In other words, the factor scores are calculated as exact linear combinations of their indicators. PLS regression is the underlying weight calculation algorithm used in both Warp3 and Warp2 PLS Regression. The warping takes place during the estimation of path coefficients, and after the estimation of all weights and loadings in the model. The weights and loadings of a model with latent variables make up what is often referred to as outer model, whereas the path coefficients among latent variables make up what is often called the inner model.
Finally, the Robust Path Analysis algorithm is a simplified algorithm in which factor scores are calculated by averaging all of the indicators associated with a latent variable; that is, in this algorithm weights are not estimated through PLS regression. This algorithm is called “Robust” Path Analysis, because, as with most robust statistics methods, the P values are calculated through resampling. If all latent variables are measured with single indicators, the Robust Path Analysis and the PLS Regression algorithms will yield identical results.
Okay, so what algorithm should you use?
Generally it will be one of these: Warp3 PLS Regression, Warp2 PLS Regression, PLS Regression. Only in a small number of instances, quite rare, will the Robust Path Analysis algorithm be the best choice.
If you analyze your dataset using different algorithms (e.g., Warp3 PLS Regression, Warp2 PLS Regression, and PLS Regression), usually the “best” algorithm will be the one leading to the most stable path coefficients. The most stable path coefficients are the ones with the lowest P values, whether the P values are obtained through bootstrapping or jackknifing. The best algorithm will also be the one leading to the highest average R-squared (ARS).
Another important consideration is theory. Does the theory underlying a hypothesized relationship between latent variables support the expectation of a U-curve or S-curve relationship? If the theory supports the expectation of a U-curve relationship, but not of an S-curve relationship, then you should favor Warp2 PLS Regression over Warp3 PLS Regression, even if the latter leads to the most stable path coefficients (i.e., with the lowest P values).
Friday, April 30, 2010
Naming of latent variable indicators in WarpPLS
The indicator names are the headings of your raw data file, which are also shown on a few software screens during Step 2. That is the step where you read the raw data used in the SEM analysis. The indicator names are displayed at the top of the table on the figure below, a screen from Step 3; click on it to enlarge.
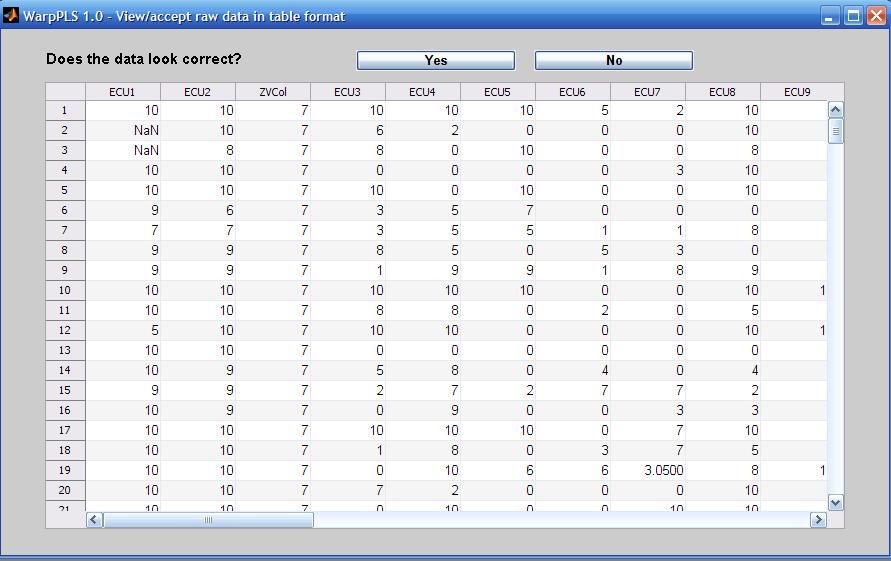
The software does not force users to restrict the names of indicators to a set number of characters (e.g., seven), or to exclude certain types of characters (e.g., blank spaces) from them. Nevertheless, it is usually a good idea to follow a few simple rules when naming indicators:
- Make the indicator names 7 characters in length, or less. This will ensure that they will not take up too much space on various screens and reports. In fact, in reports saved in text files, any character after the seventh is removed by the software. Otherwise the text file will become difficult to read without manual editing.
- Name the indicators using their latent variable name as a reference, and using sequential numbers at the end. For example, indicators that refer to the latent variable “ECU” should be named: “ECU1”, “ECU2”, “ECU3”, and so on.
- Do not use blank spaces in the indicator names. If you do, and an indicator name is long, the software may show the indicator split on two different rows on the model screen (Step 4), when you choose to show indicators on the model.
Friday, March 26, 2010
Interpreting the U and S curves generated by WarpPLS
Linear relationships between pairs of latent variables, that is, those relationships best described by a line, are relatively easy to interpret. They suggest that an increase in one variable either leads to an increase (if the slope of the line is positive) or decrease (if the slope is negative) in the other variable.
Nonlinear relationships provide a much more nuanced view of the data, but at the same time are much more difficult to interpret correctly. The graph below (click on it to enlarge) shows an S curve that is fitted to the data represented by the dots (or small circles) plotted in a scattered way on the graph. The latent variables are “ECU”, the extent to which electronic communication media are used by a team charged with developing a new product; and “Effi”, the efficiency of the team.
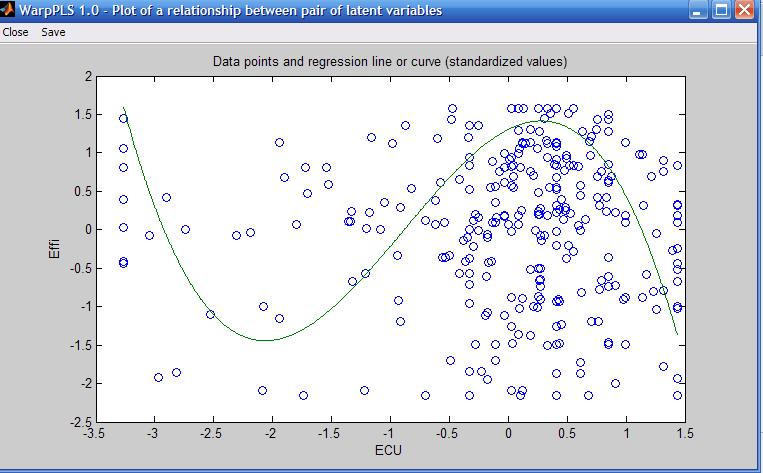
As you can see, the S curve is actually a combination of two U curves, one straight and the other inverted, connected at an inflection point. The inflection point is the point at the curve where the curvature, or second derivative of the S curve, changes direction. On the graph shown above, the inflection point is located at around minus 1 standard deviations from the "ECU" mean. That mean is at the zero mark on the horizontal axis.
Because an S curve is a combination of two U curves, we can interpret each U curve section separately. A straight U curve, like the one shown on the left side of the graph, before the inflection point, can be interpreted as follows.
The first half of the U curve goes from approximately minus 3.4 to minus 1.9 standard deviations from the mean, at which point the lowest team efficiency value is reached for the U curve. In that first half of the U curve, an increase in electronic communication media use leads to a decrease in team efficiency. After that first half, an increase in electronic communication media use leads to an increase in team efficiency.
One interpretation is that the first half of the U curve refers to novice users of electronic communication media. That is, novice users struggling to use more and more intensely communication media that they are not familiar with end up leading to efficiency losses for the team. At a certain point, around minus 1.9 standard deviations, that situation changes, and the teams start to really benefit from the use of electronic communication media, possibly because the second half of the U curve refers to users with more experience in using the media.
The interpretation of the second, inverted U curve, should be done in a similar fashion. As you can see, it is not easy to interpret nonlinear relationships. But the apparent simplicity of linear estimations of nonlinear relationships, which is usually what is done by other structural equation modeling software, is nothing but a mirage.
Monday, March 22, 2010
Field studies, small samples, and WarpPLS
Let us assume that a researcher wants to evaluate the effectiveness of new management method by conducting an intervention study in one single organization.
In this example, the researcher facilitates the use of a new management method by 20 managers in the organization, and then measures their degree of adoption of the method and their effectiveness.
The above is an example of a field study. Often field studies will yield small datasets, which will not conform to parametric analysis (e.g., ANOVA and ordinary multiple regression) pre-conditions. For example, the data will not typically be normally distributed.
WarpPLS can be very useful in the analysis of this type of data.
One reason is that, with small sample sizes, it may be difficult to identify linear relationships that are strong enough to be statistically significant (at P lower than 0.05, or less). Since WarpPLS implements nonlinear analysis algorithms, it can be very useful in the analysis of small samples.
Another reason is that P values are calculated through resampling, a nonparametric approach to statistical significance estimation. For small samples (i.e., lower than 100), jackknifing is the recommended resampling approach. Bootstrapping is recommended only for sample sizes greater than 100.
Monday, March 15, 2010
Standard deviation is not the same as range of variation
Means and standard deviations can be generated and saved through the “Save grouped descriptive statistics into a tab-delimited .txt file” option of WarpPLS. You can choose a grouping variable, number of groups, and the variables to be grouped. This option is useful if one wants to conduct a comparison of means analysis using the software, where one variable (the grouping variable) is the predictor, and one or more variables are the criteria (the variables to be grouped).
In comparisons of means analyses, research results are normally expressed in means and standard deviations. For example, in the study reviewed in this post, it is stated that the weight of participants in a 12-week weight loss study varied from: 87.9 plus or minus 15.4 kg (at baseline, or before the 12-week intervention) to 81.7 plus or minus 16.2 kg (after the 12-week intervention).
The 87.9 and 81.7 are the average weights (a.k.a. “mean” weights), in kilograms, before and after the 12-week intervention. However, the 15.4 and 16.2 are NOT the range of variation in weights around the means before and after 12-week intervention. They are actually the ranges around the means encompassing approximately 68 percent of all of the values measured (see figure below, from www.electrical-res.com).

In the figure above, the minus and plus 15.4 and 16.2 values would be the “mean(x) – s” and “mean(x) + s” points on the horizontal axis of histograms of weights plotted before and after the 12-week intervention. This assumes that the distributions of weights are normal, or quasi-normal (i.e., similar to a bell-shaped, or normal, curve); a common assumption in this type of research.
The larger the standard deviation, the wider is the variation in the measures, and the flatter is the associated histogram (the bell-shaped curve). This property has a number of interesting implications, some of which will be discussed in other posts.
Sometimes another measure of dispersion, the variance, is reported instead of the standard deviation. The variance is the standard deviation squared.
The reason why standard deviations are reported instead of ranges of variation is that outliers (unusually high or low values) can dramatically widen the ranges. The standard deviation coefficient is much less sensitive to outliers.
Tuesday, March 2, 2010
Geographically distributed collaborative SEM analysis using WarpPLS
I am currently conducting a geographically distributed collaborative SEM analysis using WarpPLS. The analysis involves a few people in different states of the USA, and two people outside the country. The collaborators are not only separated by large distances, but also operate in different time zones.
Yet, we have no problems collaborating. The collaboration is asynchronous – one person does some work one day, and shares it with the others, who review the work in the next few days and respond.
Since we all have WarpPLS installed on our computers, we exchange different versions of a WarpPLS project file (extension “.prj”) with the same dataset. This way we can do analyses in turns, and discuss the results on emails.
Each slightly different project file is saved with a different name – e.g., W3J_InfoOvld_2010_03_02.prj, W3B_InfoOvld_2010_03_02.prj, W2J_InfoOvld_2010_03_02.prj etc.
In the examples above, the first three letters indicate the SEM algorithm used (W3 = Warp3 PLS Regression; W2 = Warp2 PLS Regression), and the resampling method used (J = jackknifing; B = bootstrapping). The second part of the name describes the dataset, and the final part the date.
This is just one way of naming files. It works for our particular project, but more elaborate file names can be used in more complex collaborative SEM analyses.
This geographically distributed collaborative SEM analysis highlights one of the advantages of WarpPLS over other SEM software: all that is needed for the analysis is contained in one single project file.
Moreover, the project file will typically be only a few hundred kilobytes in size. In spite of its small size, the file includes the original data, and all of the results of the analysis.
One member of our team asked me how the project file can be so small. The reason is that all of the SEM analysis results are stored in a format that allows for their rendering every time they are viewed.
Plots of nonlinear relationships, for example, are not stored as bitmaps, but as equations that allow WarpPLS to re-create those plots at the time of viewing.
Sunday, February 21, 2010
What are the inner and outer models in SEM?
In a structural equation modeling (SEM) analysis, the inner model is the part of the model that describes the relationships among the latent variables that make up the model. The outer model is the part of the model that describes the relationships among the latent variables and their indicators.
In this sense, the path coefficients are inner model parameter estimates. The weights and loadings are outer model parameter estimates. The inner and outer models are also frequently referred to as the structural and measurement models, respectively.
More precisely, the mathematical equations that express the relationships among latent variables are referred to as the structural model. The equations that express the relationships among latent variables and indicators are referred to as the measurement model.
The term structural equation model is used to refer to both the structural and measurement model, combined.
Nonlinearity and type I and II errors in SEM analysis
Many relationships between variables studied in the natural and behavioral sciences seem to be nonlinear, often following a J-curve pattern (a.k.a. U-curve pattern). Other common relationships include the logarithmic, hyperbolic decay, exponential decay, and exponential. These and other relationships are modeled by WarpPLS.
Yet, the vast majority of statistical analysis methods used in the natural and behavioral sciences, from simple correlation analysis to structural equation modeling, assume relationships to be linear in the estimation of coefficients of association (e.g., Pearson correlations, standardized partial regression coefficients).
This may significantly distort results, especially in multivariate analyses, increasing the likelihood that researchers will commit type I and II errors in the same study. A type I error occurs in SEM analysis when an insignificant (the technical term is "non-significant") association is estimated as being significant (i.e., a “false positive”); a type II error occurs when a significant association is estimated as being insignificant (i.e., an existing association is “missed”).
The figure below shows a distribution of points typical of a J-curve pattern involving two variables, disrupted by uncorrelated error. The pattern, however, is modeled as a linear relationship. The line passing through the points is the best linear approximation of the distribution of points. It yields a correlation coefficient of .582. In this situation, the variable on the horizontal axis explains 33.9 percent of the variance of the variable on the vertical axis.

The figure below shows the same J-curve scatter plot pattern, but this time modeled as a nonlinear relationship. The curve passing through the points is the best nonlinear approximation of the distribution of the underlying J-curve, and excludes the uncorrelated error. That is, the curve does not attempt to model the uncorrelated error, only the underlying nonlinear relationship. It yields a correlation coefficient of .983. Here the variable on the horizontal axis explains 96.7 percent of the variance of the variable on the vertical axis.

WarpPLS transforms (or “warps”) J-curve relationship patterns like the one above BEFORE the corresponding path coefficients between each pair of variables are calculated. It does the same for many other nonlinear relationship patterns. In multivariate analyses, this may significantly change the values of the path coefficients, reducing the risk that researchers will commit type I and II errors.
The risk of committing type I and II errors is particularly high when: (a) a block of latent variables includes multiple predictor variables pointing and the same criterion variable; (b) one or more relationships between latent variables are significantly nonlinear; and (c) the predictor latent variables are correlated, even if they clearly measure different constructs (suggested by low variance inflation factors).
Sunday, February 14, 2010
How do I control for the effects of one or more demographic variables in an SEM analysis?
As part of an SEM analysis using WarpPLS, a researcher may want to control for the effects of one ore more variables. This is typically the case with what are called “demographic variables”, or variables that measure attributes of a given unit of analysis that are (usually) not expected to influence the results of the SEM analysis.
For example, let us assume that one wants to assess the effect of a technology, whose intensity of use is measured by a latent variable T, on a behavioral variable measured by B. The unit of analysis for B is the individual user; that is, each row in the dataset refers to an individual user of the technology. The researcher hypothesizes that the association between T and B is significant, so a direct link between T and B is included in the model.
If the researcher wants to control for age (A) and gender (G), which have also been collected for each individual, in relation to B, all that is needed is to include the variables A and G in the model, with direct links pointing at B. No hypotheses are made. For that to work, gender (G) has to be included in the dataset as a numeric variable. For example, the gender "male" may be replaced with 1 and "female" with 2, in which case the variable G will essentially measure the "degree of femaleness" of each individual. Sounds odd, but works.
After the analysis is conducted, let us assume that the path coefficient between T and B is found to be statistically significant, with the variables A and G included in the model as described above. In this case, the researcher can say that the association between T and B is significant, “regardless of A and G” or “when the effects of A and G are controlled for”.
In other words, the technology (T) affects behavior (B) in the hypothesized way regardless of age (A) and gender (B). This conclusion would remain the same whether the path coefficients between A and/or G and B were significant, because the focus of the analysis is on B, the main dependent variable of the model.
The discussion above is expanded in the publication below, which also contains a graphical representation of a model including control variables.
Kock, N. (2011). Using WarpPLS in e-collaboration studies: Mediating effects, control and second order variables, and algorithm choices. International Journal of e-Collaboration, 7(3), 1-13.http://www.scriptwarp.com/warppls/pubs/Kock_2011_IJeC_WarpPLSEcollab3.pdf
Some special considerations and related analysis decisions usually have to be made in more complex models, with multiple endogenous variables, and also regarding the fit indices.
Tuesday, February 9, 2010
Variance inflation factors: What they are and what they contribute to SEM analyses
Note: This post refers to the use of variance inflation factors to identify "vertical", or classic, multicolinearity. For a broader discussion of variance inflation factors in the context of "lateral" and "full" collinearity tests, please see Kock & Lynn (2012). For a discussion in the context of common method bias tests, see the post linked here.
Variance inflation factors are provided in table format by WarpPLS for each latent variable that has two or more predictors. Each variance inflation factor is associated with one predictor, and relates to the link between that predictor and its latent variable criterion. (Or criteria, when one predictor latent variable points at two or more different latent variables in the model.)
A variance inflation factor is a measure of the degree of multicolinearity among the latent variables that are hypothesized to affect another latent variable. For example, let us assume that there is a block of latent variables in a model, with three latent variables A, B, and C (predictors) pointing at latent variable D. In this case, variance inflation factors are calculated for A, B, and C, and are estimates of the multicolinearity among these predictor latent variables.
Two criteria, one more conservative and one more relaxed, are traditionally recommended in connection with variance inflation factors. More conservatively, it is recommended that variance inflation factors be lower than 5; a more relaxed criterion is that they be lower than 10 (Hair et al., 1987; Kline, 1998). High variance inflation factors usually occur for pairs of predictor latent variables, and suggest that the latent variables measure the same thing. This problem can be solved through the removal of one of the offending latent variables from the block.
References:
Hair, J.F., Anderson, R.E., & Tatham, R.L. (1987). Multivariate data analysis. New York, NY: Macmillan.
Kline, R.B. (1998). Principles and practice of structural equation modeling. New York, NY: The Guilford Press.
Kock, N., & Lynn, G.S. (2012). Lateral collinearity and misleading results in variance-based SEM: An illustration and recommendations. Journal of the Association for Information Systems, 13(7), 546-580.
Two new WarpPLS workshops in March and April 2010
PLS-SEM.com will conduct two new online workshops on WarpPLS in March and April 2010!
For more information on these and other WarpPLS workshops please visit:
Thursday, February 4, 2010
Reading data into WarpPLS: An easy and flexible step
Through Step 2, you will read the raw data used in the SEM analysis. While this should be a relatively trivial step, it is in fact one of the steps where users have the most problems with other SEM software. Often an SEM software application will abort, or freeze, if the raw data is not in the exact format required by the SEM software, or if there are any problems with the data, such as missing values (empty cells).
WarpPLS employs an import "wizard" that avoids most data reading problems, even if it does not entirely eliminate the possibility that a problem will occur. Click only on the “Next” and “Finish” buttons of the file import wizard, and let the wizard to the rest. Soon after the raw data is imported, it will be shown on the screen, and you will be given the opportunity to accept or reject it. If there are problems with the data, such as missing column names, simply click “No” when asked if the data looks correct.
Raw data can be read directly from Excel files, with extension “.xls” (or newer Excel extensions), or text files where the data is tab-delimited or comma-delimited. When reading from an “.xls” file, make sure that the spreadsheet file that has your numeric data is in the first worksheet; that is, if the spreadsheet has multiple worksheets. Raw data files, whether Excel or text files, must have indicator names in the first row, and numeric data in the following rows. They may contain empty cells, or missing values; these will be automatically replaced with column averages in a later step (assuming that the default missing data imputation algorithm is used).
One simple test can be used to try to find out if there are problems with a raw data file. Try to open it with a spreadsheet software (e.g., Excel), if it is originally a text file; or try to create a tab-delimited text file with it, if it is originally a spreadsheet file. If you try to do either of these things, and the data looks messed up (e.g., corrupted, or missing column names), then it is likely that the original file has problems, which may be hidden from view. For example, a spreadsheet file may be corrupted, but that may not be evident based on a simple visual inspection of the contents of the file.
Sunday, January 31, 2010
Project files in WarpPLS: Small but information-rich
Project files in WarpPLS are saved with the “.prj” extension, and contain all of the elements needed to perform an SEM analysis. That is, they contain the original data used in the analysis, the graphical model, the inner and outer model structures, and the results.
Once an original data file is read into a project file, the original data file can be deleted without effect on the project file. The project file will store the original location and file name of the data file, but it will no longer use it.
Project files may be created with one name, and then renamed using Windows Explorer or another file management tool. Upon reading a project file that has been renamed in this fashion, the software will detect that the original name is different from the file name, and will adjust the name of the project file accordingly.
Different users of this software can easily exchange project files electronically if they are collaborating on a SEM analysis project. This way they will have access to all of the original data, intermediate data, and SEM analysis results in one single file.
Project files are relatively small. For example, a complete project file of a model containing 5 latent variables and 32 indicators will typically be only approximately 200 KB in size. Simpler models may be stored in project files as small as 50 KB.
Saturday, January 30, 2010
Reflective and formative latent variable measurement in WarpPLS
A reflective latent variable is one in which all the indicators are expected to be highly correlated with the latent variable score. For example, the answers to certain question-statements by a group of people, measured on a 1 to 7 scale (1=strongly disagree; 7 strongly agree) and answered after a meal, are expected to be highly correlated with the latent variable “satisfaction with a meal”. The question-statements are: “I am satisfied with this meal”, and “After this meal, I feel good”. Therefore, the latent variable “satisfaction with a meal”, can be said to be reflectively measured through two indicators. Those indicators store answers to the two question-statements. This latent variable could be represented in a model graph as “Satisf”, and the indicators as “Satisf1” and “Satisf2”.
A formative latent variable is one in which the indicators are expected to measure certain attributes of the latent variable, but the indicators are not expected to be highly correlated with the latent variable score, because they (i.e., the indicators) are not expected to be highly correlated with one another. For example, let us assume that the latent variable “Satisf” (“satisfaction with a meal”) is now measured using the two following question-statements: “I am satisfied with the main course” and “I am satisfied with the dessert”. Here, the meal comprises the main course, say, filet mignon; and a dessert, a fruit salad. Both main course and dessert make up the meal (i.e., they are part of the same meal) but their satistisfaction indicators are not expected to be highly correlated with each other. The reason is that some people may like the main course very much, and not like the dessert. Conversely, other people may be vegetarians and hate the main course, but may like the dessert very much.
If the indicators are not expected to be highly correlated with one anoother, they cannot be expected to be highly correlated with their latent variable’s score. So here is a general rule of thumb that can be used to decide if a latent variable is reflectively or formatively measured. If the indicators are expected to be highly correlated, then the measurement model should be set as reflective in WarpPLS. If the indicators are not expected to be highly correlated, even though they clearly refer to the same latent variable, then the measurement model should be set as formative.
Thursday, January 28, 2010
Bootstrapping or jackknifing (or both) in WarpPLS?
The blog post below refers to resampling methods, notably bootstrapping and jackknifing, which are often used for the generation of estimates employed and hypothesis testing. Even though they are widely used, resampling methods are inherently unstable. More recent versions of WarpPLS employ "stable" methods for the same purpose, with various advantages. See the most recent version of the WarpPLS User Manual (linked below) for more details.
http://www.scriptwarp.com/warppls/#User_Manual
Arguably jackknifing does a better job at addressing problems associated with the presence of outliers due to errors in data collection. Generally speaking, jackknifing tends to generate more stable resample path coefficients (and thus more reliable P values) with small sample sizes (lower than 100), and with samples containing outliers. In these cases, outlier data points do not appear more than once in the set of resamples, which accounts for the better performance of jackknifing (see, e.g., Chiquoine & Hjalmarsson, 2009).
Bootstrapping tends to generate more stable resample path coefficients (and thus more reliable P values) with larger samples and with samples where the data points are evenly distributed on a scatter plot. The use of bootstrapping with small sample sizes (lower than 100) has been discouraged (Nevitt & Hancock, 2001).
Since the warping algorithms are also sensitive to the presence of outliers, in many cases it is a good idea to estimate P values with both bootstrapping and jackknifing, and use the P values associated with the most stable coefficients. An indication of instability is a high P value (i.e., statistically insignificant) associated with path coefficients that could be reasonably expected to have low P values. For example, with a sample size of 100, a path coefficient of .2 could be reasonably expected to yield a P value that is statistically significant at the .05 level. If that is not the case, there may be a stability problem. Another indication of instability is a marked difference between the P values estimated through bootstrapping and jackknifing.
P values can be easily estimated using both resampling methods, bootstrapping and jackknifing, by following this simple procedure. Run an SEM analysis of the desired model, using one of the resampling methods, and save the project. Then save the project again, this time with a different name, change the resampling method, and run the SEM analysis again. Then save the second project again. Each project file will now have results that refer to one of the two resampling methods. The P values can then be compared, and the most stable ones used in a research report on the SEM analysis.
References:
Chiquoine, B., & Hjalmarsson, E. (2009). Jackknifing stock return predictions. Journal of Empirical Finance, 16(5), 793-803.
Nevitt, J., & Hancock, G.R. (2001). Performance of bootstrapping approaches to model test statistics and parameter standard error estimation in structural equation modeling. Structural Equation Modeling, 8(3), 353-377.
http://www.scriptwarp.com/warppls/#User_Manual
***
Arguably jackknifing does a better job at addressing problems associated with the presence of outliers due to errors in data collection. Generally speaking, jackknifing tends to generate more stable resample path coefficients (and thus more reliable P values) with small sample sizes (lower than 100), and with samples containing outliers. In these cases, outlier data points do not appear more than once in the set of resamples, which accounts for the better performance of jackknifing (see, e.g., Chiquoine & Hjalmarsson, 2009).
Bootstrapping tends to generate more stable resample path coefficients (and thus more reliable P values) with larger samples and with samples where the data points are evenly distributed on a scatter plot. The use of bootstrapping with small sample sizes (lower than 100) has been discouraged (Nevitt & Hancock, 2001).
Since the warping algorithms are also sensitive to the presence of outliers, in many cases it is a good idea to estimate P values with both bootstrapping and jackknifing, and use the P values associated with the most stable coefficients. An indication of instability is a high P value (i.e., statistically insignificant) associated with path coefficients that could be reasonably expected to have low P values. For example, with a sample size of 100, a path coefficient of .2 could be reasonably expected to yield a P value that is statistically significant at the .05 level. If that is not the case, there may be a stability problem. Another indication of instability is a marked difference between the P values estimated through bootstrapping and jackknifing.
P values can be easily estimated using both resampling methods, bootstrapping and jackknifing, by following this simple procedure. Run an SEM analysis of the desired model, using one of the resampling methods, and save the project. Then save the project again, this time with a different name, change the resampling method, and run the SEM analysis again. Then save the second project again. Each project file will now have results that refer to one of the two resampling methods. The P values can then be compared, and the most stable ones used in a research report on the SEM analysis.
References:
Chiquoine, B., & Hjalmarsson, E. (2009). Jackknifing stock return predictions. Journal of Empirical Finance, 16(5), 793-803.
Nevitt, J., & Hancock, G.R. (2001). Performance of bootstrapping approaches to model test statistics and parameter standard error estimation in structural equation modeling. Structural Equation Modeling, 8(3), 353-377.
How many resamples to use in bootstrapping?
The default number of resamples is 100 for bootstrapping in WarpPLS. This setting can be modified by entering a different number in the appropriate edit box. (Please note that we are talking about the number of resamples here, not the original data sample size.)
Leaving the number of resamples for bootstrapping as 100 is recommended because it has been shown that higher numbers of resamples lead to negligible improvements in the reliability of P values; in fact, even setting the number of resamples at 50 is likely to lead to fairly reliable P value estimates (Efron et al., 2004).
Conversely, increasing the number of resamples well beyond 100 leads to a higher computation load on the software, making the software look like it is having a hard time coming up with the results. In very complex models, a high number of resamples may make the software run very slowly.
Some researchers have suggested in the past that a large number of resamples can address problems with the data, such as the presence of outliers due to errors in data collection. This opinion is not shared by the original developer of the bootstrapping method, Bradley Efron (see, e.g., Efron et al., 2004).
Reference:
Efron, B., Rogosa, D., & Tibshirani, R. (2004). Resampling methods of estimation. In N.J. Smelser, & P.B. Baltes (Eds.). International Encyclopedia of the Social & Behavioral Sciences (pp. 13216-13220). New York, NY: Elsevier.
Viewing and changing settings in WarpPLS 1.0 and 2.0
The blog post below refers to version 1.0 - 2.0 of WarpPLS. See this YouTube video on how to view and change settings for version 3.0. For more recent versions, see the WarpPLS User Manual and YouTube videos available from warppls.com.
***
The view or change settings window (see figure below, click on it to enlarge) allows you to select an algorithm for the SEM analysis, select a resampling method, and select the number of resamples used, if the resampling method selected was bootstrapping. The analysis algorithms available are Warp3 PLS Regression, Warp2 PLS Regression, PLS Regression, and Robust Path Analysis.

Many relationships in nature, including relationships involving behavioral variables, are nonlinear and follow a pattern known as U-curve (or inverted U-curve). In this pattern a variable affects another in a way that leads to a maximum or minimum value, where the effect is either maximized or minimized, respectively. This type of relationship is also referred to as a J-curve pattern; a term that is more commonly used in economics and the health sciences.
The Warp2 PLS Regression algorithm tries to identify a U-curve relationship between latent variables, and, if that relationship exists, the algorithm transforms (or “warps”) the scores of the predictor latent variables so as to better reflect the U-curve relationship in the estimated path coefficients in the model. The Warp3 PLS Regression algorithm, the default algorithm used by the software, tries to identify a relationship defined by a function whose first derivative is a U-curve. This type of relationship follows a pattern that is more similar to an S-curve (or a somewhat distorted S-curve), and can be seen as a combination of two connected U-curves, one of which is inverted.
The PLS Regression algorithm does not perform any warping of relationships. It is essentially a standard PLS regression algorithm, whereby indicators’ weights, loadings and factor scores (a.k.a. latent variable scores) are calculated based on a least squares minimization sub-algorithm, after which path coefficients are estimated using a robust path analysis algorithm. A key criterion for the calculation of the weights, observed in virtually all PLS-based algorithms, is that the regression equation expressing the relationship between the indicators and the factor scores has an error term that equals zero. In other words, the factor scores are calculated as exact linear combinations of their indicators. PLS regression is the underlying weight calculation algorithm used in both Warp3 and Warp2 PLS Regression. The warping takes place during the estimation of path coefficients, and after the estimation of all weights and loadings in the model. The weights and loadings of a model with latent variables make up what is often referred to as outer model, whereas the path coefficients among latent variables make up what is often called the inner model.
Finally, the Robust Path Analysis algorithm is a simplified algorithm in which factor scores are calculated by averaging all of the indicators associated with a latent variable; that is, in this algorithm weights are not estimated through PLS regression. This algorithm is called “Robust” Path Analysis, because, as with most robust statistics methods, the P values are calculated through resampling. If all latent variables are measured with single indicators, the Robust Path Analysis and the PLS Regression algorithms will yield identical results.
One of two resampling methods may be selected: bootstrapping or jackknifing. Bootstrapping, the software’s default, is a resampling algorithm that creates a number of resamples (a number that can be selected by the user), by a method known as “resampling with replacement”. This means that each resample contains a random arrangement of the rows of the original dataset, where some rows may be repeated. (The commonly used analogy of a deck of cards being reshuffled, leading to many resample decks, is a good one, but not entirely correct because in bootstrapping the same card may appear more than once in each of the resample decks.) Jacknifing, on the other hand, creates a number of resamples that equals the original sample size, and each resample has one row removed. That is, the sample size of each resample is the original sample size minus 1. Thus, the choice of number of resamples has no effect on jackknifing, and is only relevant in the context of bootstrapping.
Saving and using grouped descriptive statistics in WarpPLS
When the “Save grouped descriptive statistics into a tab-delimited .txt file” option is selected, a data entry window is displayed. There you can choose a grouping variable, number of groups, and the variables to be grouped. This option is useful if one wants to conduct a comparison of means analysis using the software, where one variable (the grouping variable) is the predictor, and one or more variables are the criteria (the variables to be grouped).
The figure below (click on it to enlarge) shows the grouped statistics data saved through the “Save grouped descriptive statistics into a tab-delimited .txt file” option. The tab-delimited .txt file was opened with a spreadsheet program, and contained the data on the left part of the figure.

That data on the left part of the figure was organized as shown above the bar chart; next the bar chart was created using the spreadsheet program’s charting feature. If a simple comparison of means analysis using this software had been conducted in which the grouping variable (in this case, an indicator called “ECU1”) was the predictor, and the criterion was the indicator called “Effe1”, those two variables would have been connected through a path in a simple path model with only one path. Assuming that the path coefficient was statistically significant, the bar chart displayed in the figure, or a similar bar chart, could be added to a report describing the analysis.
The following article goes into some detail about this procedure, contrasting it with other approaches:
Kock, N. (2013). Using WarpPLS in e-collaboration studies: What if I have only one group and one condition? International Journal of e-Collaboration, 9(3), 1-12.
Some may think that it is an overkill to conduct a comparison of means analysis using an SEM software package such as this, but there are advantages in doing so. One of those advantages is that this software calculates P values using a nonparametric class of estimation techniques, namely resampling estimation techniques. (These are sometimes referred to as bootstrapping techniques, which may lead to confusion since bootstrapping is also the name of a type of resampling technique.) Nonparametric estimation techniques do not require the data to be normally distributed, which is a requirement of other comparison of means techniques (e.g., ANOVA).
Another advantage of conducting a comparison of means analysis using this software is that the analysis can be significantly more elaborate. For example, the analysis may include control variables (or covariates), which would make it equivalent to an ANCOVA test. Finally, the comparison of means analysis may include latent variables, as either predictors or criteria. This is not usually possible with ANOVA or commonly used nonparametric comparison of means tests (e.g., the Mann-Whitney U test).
Saturday, January 23, 2010
How is the warping done in WarpPLS?
WarpPLS does linear and nonlinear analyses. That is, users can set WarpPLS to estimate parameters based on a standard linear algorithm, and without any warping. They can also choose one of two nonlinear algorithms, thus taking advantage of the warping capabilities of the software.
In nonlinear analyses, what WarpPLS does is relatively simple at a conceptual level. It identifies a set of functions F1(LVp1), F2(LVp2) … that relate blocks of latent variable predictors (LVp1, LVp2 ...) to a criterion latent variable (LVc) in this way:
LVc = p1*F1(LVp1) + p2*F2(LVp2) + … + E.
In the equation above, p1, p2 ... are path coefficients, and E is the error term of the equation. All variables are standardized. Any model can be decomposed into a set of blocks relating latent variable predictors and criteria in this way.
In the Warp2 mode, the functions F1(LVp1), F2(LVp2) ... take the form of U curves (also known as J curves); defaulting to lines, if the relationships are linear. The term "U curve" is used here for simplicity, as noncyclical nonlinear relationships (e.g., exponential growth) can be represented through sections of straight or rotated U curves; the term "S curve" is also used here for simplicity.
In the Warp3 mode, the functions F1(LVp1), F2(LVp2) ... take the form of S curves; defaulting to U curves or lines, if the relationships follow U-curve patterns or are linear, respectively.
S curves are curves whose first derivative is a U curve. Similarly, U curves are curves whose first derivative is a line. U curves seem to be the most commonly found in natural and behavioral phenomena. S curves are also found, but apparently not as frequently as U curves.
U curves can be used to model most of the commonly seen functions in natural and behavioral studies, such as logarithmic, exponential, and hyperbolic decay functions. For these common types of functions, S-curve approximations will usually default to U curves.
Other types of curves beyond S curves might be found in specific types of situations, and require specialized analysis methods that are typically outside the scope of structural equation modeling. Examples are time series and Fourier analyses. Therefore these are beyond the scope of application of WarpPLS.
Typically, the more the functions F1(LVp1), F2(LVp2) ... look like curves, and unlike lines, the greater is the difference between the path coefficients p1, p2 ... and those that would have been obtained through a strictly linear analysis.
So, what WarpPLS does is not unlike what a researcher would do if he or she modified predictor latent variables prior to the calculation of path coefficients using a function like the logarithmic function. For example, as in the equation below, where a log transformation is applied to LVp1.
LVc = p1*log(LVp1) + p2*LVp2 + … + E.
However, WarpPLS does that automatically, and for a much wider range of functions, since a fairly wide range of functions can be modeled as U or S curves. Exceptions are complex trigonometric functions, where the dataset comprises many cycles. These require different methods to be properly modeled, such as the Fourier analyses methods mentioned above, and are usually outside the scope of structural equation modeling (SEM; which is the analysis method that WarpPLS automates).
Often the path coefficients p1, p2 ... will go up in value due to warped analysis, but that may not always be the case. Given the nature of multivariate analysis, an increase in a path coefficient may lead to a decrease in a path coefficient for an arrow pointing at the same criterion latent variable, because each path coefficient in a block is calculated in a way that controls for the effects of the other predictor latent variables.
How are the model fit indices calculated by WarpPLS?
WarpPLS is unique among software that implement PLS-SEM algorithms in that it provides users with a number of model-wide fit indices; arguably more than any other SEM software. Three of the main model fit indices calculated by WarpPLS are the following: average path coefficient (APC), average R-squared (ARS), and average variance inflation factor (AFVIF).
They are discussed in the WarpPLS User Manual, which is available separately from the software, as a standalone document, on the WarpPLS web site.
These fit indices (there are several others) are calculated as their name implies, that is, as averages of: the (absolute values of the ) path coefficients in the model, the R-squared values in the model, and the variance inflation factors in the model. All of these are also provided individually by the software.
These fit indices (there are several others) are calculated as their name implies, that is, as averages of: the (absolute values of the ) path coefficients in the model, the R-squared values in the model, and the variance inflation factors in the model. All of these are also provided individually by the software.
The P values for APC and ARS are calculated through re-sampling. A correction is made to account for the fact that these indices are calculated based on other parameters, which leads to a biasing effect – a variance reduction effect associated with the central limit theorem.
Typically the addition of new latent variables into a model will increase the ARS, even if those latent variables are weakly associated with the existing latent variables in the model. However, that will generally lead to a decrease in APC, since the path coefficients associated with the new latent variables will be low. Thus, the APC and ARS will counterbalance each other, and will only increase together if the latent variables that are added to the model enhance the overall predictive and explanatory quality of the model.
The AFVIF index will increase if new latent variables are added to the model in such a way as to add multicolinearity to the model, which may result from the inclusion of new latent variables that overlap in meaning with existing latent variables. It is generally undesirable to have different latent variables in the same model that measure the same thing; those should be combined into one single latent variable. Thus, the AFVIF brings in a new dimension that adds to a comprehensive assessment of a model’s overall predictive and explanatory quality.
Starting in version 6.0 of WarpPLS, new indices are available that allow investigators to assess the fit between the model-implied and empirical indicator correlation matrices. These new indices are available from the "Explore" menu option, after Step 5 is completed. They are discussed on page 26 of the WarpPLS User Manual for version 6.0, and on a video clip (links below).
http://www.scriptwarp.com/warppls/UserManual_v_6_0.pdf#page=26
https://youtu.be/YutkhEPW-CE
Starting in version 6.0 of WarpPLS, new indices are available that allow investigators to assess the fit between the model-implied and empirical indicator correlation matrices. These new indices are available from the "Explore" menu option, after Step 5 is completed. They are discussed on page 26 of the WarpPLS User Manual for version 6.0, and on a video clip (links below).
http://www.scriptwarp.com/warppls/UserManual_v_6_0.pdf#page=26
https://youtu.be/YutkhEPW-CE
https://scriptwarp.com/dapj
As a final note, I would like to point out that the interpretation of the model fit indices depends on the goal of the SEM analysis. If the goal is to test hypotheses, where each arrow represents a hypothesis, then the model fit indices are of some importance, but in a limited way. However, if the goal is to find out whether one model has a better fit with the original data than another, then the model fit indices become more important, and are a useful set of measures related to model quality.
Friday, January 22, 2010
Why are pattern cross-loadings so low in WarpPLS?
I have recently received a few related questions from WarpPLS users. Essentially, they noted that the pattern loadings generated by WarpPLS were very similar to those generated by other PLS-based SEM software. However, they wanted to know why the pattern cross-loadings were so much lower in WarpPLS, compared to other PLS-based SEM software.
Low cross-loadings suggest good discriminant validity; a type of validity that is usually tested via WarpPLS using a separate procedure, involving tabulation of latent variable correlations and average variances extracted.
Nevertheless, low cross-loadings, combined with high loadings, are a "good thing" (generally speaking) in the context of a PLS-based SEM analysis.
The pattern loadings and cross-loadings provided by WarpPLS are from a pattern matrix, which is obtained after the transformation of a structure matrix through an oblique rotation (similar to Promax).
The structure matrix contains the Pearson correlations between indicators and latent variables, which are not particularly meaningful prior to rotation in the context of measurement instrument validation (e.g., validity and reliability assessment).
In an oblique rotation the loadings shown on the pattern matrix are very similar to those on the structure matrix. The latter are the ones that other PLS-based SEM software usually report, which is why the loadings obtained through WarpPLS and other PLS-based SEM software are very similar. The cross-loadings though, can be very different in the pattern (rotated) matrix, as these WarpPLS users noted.
In short, the reason for the comparatively low cross-loadings is the oblique rotation employed by WarpPLS.
Here is a bit more information regarding rotation methods:
Because an oblique rotation is employed by WarpPLS, in some (relatively rare) cases pattern loadings may be higher than 1, which should have no effect on their interpretation. The expectation is that pattern loadings, which are shown within parentheses (on the "View indicator loadings and cross-loadings" option), will be high; and cross-loadings will be low.
The combined loadings and cross-loadings table always shows loadings lower than 1, because that table combines structure loadings with pattern cross-loadings. This obviates the need for a normalization step, which can distort loadings and cross-loadings somewhat.
Also, let me add that the main difference between oblique and orthogonal rotation methods (e.g., Varimax) is that the former assume that there are correlations, some of which may be strong, among latent variables.
Arguably oblique rotation methods are the most appropriate in PLS-based SEM analysis, because by definition latent variables are expected to be correlated. Otherwise, no path coefficient would be significant.
Technically speaking, it is possible that a research study will hypothesize only neutral relationships between latent variables, which could call for an orthogonal rotation. However, this is rarely, if ever, the case.
See the most recent version of the WarpPLS User Manual (linked below) for more details.
http://www.scriptwarp.com/warppls/#User_Manual
See the most recent version of the WarpPLS User Manual (linked below) for more details.
http://www.scriptwarp.com/warppls/#User_Manual
Thursday, January 21, 2010
WarpPLS running on a Mac? Sure!
When WarpPLS was first made available, I told a colleague of mine that it would probably run on a Mac without problems. Without trying, he said: No way Jose!
Then he really tried (using virtualization software, more below); it worked, and his response: Maybe u wuz royt eh!?
I have since received a few emails from WarpPLS users who own Mac computers. They run WarpPLS on those computers, without problems, even though WarpPLS was designed to be used with Windows.
How is that possible?
Those users have virtualization (a.k.a., virtual machine) software installed on their computers, which allow them to run WarpPLS on different types of computers, including Mac computers.
The virtualization software actually allows them to run the Windows operating system (typically the XP or 7 versions) on a Mac computer. They then install WarpPLS on the Windows virtual machine created by the virtualization software.
Monday, January 11, 2010
March 2010 online workshop on WarpPLS
PLS-SEM.com will conduct an online workshop on WarpPLS in March 2010!
The direct link to the workshop site is:
http://www.regonline.com/builder/site/Default.aspx?eventid=811252
The list of upcoming workshops is on:
http://pls-sem.com/cgi-bin/p/awtp-custom.cgi?d=plssem&page=10403
The direct link to the workshop site is:
http://www.regonline.com/builder/site/Default.aspx?eventid=811252
The list of upcoming workshops is on:
http://pls-sem.com/cgi-bin/p/awtp-custom.cgi?d=plssem&page=10403
Saturday, January 2, 2010
Solve collinearity problems in WarpPLS: YouTube video
A new YouTube video for WarpPLS is available; please see link below.
http://www.youtube.com/watch?v=avPWO324E0g
The video shows how problems associated with latent variable collinearity, suggested by unstable path coefficients and high variance inflation factors, can be solved in a structural equation modeling (SEM) analysis using the software WarpPLS.
Note that this type of problem is different from problems related to indicators having low loadings and high cross-loadings. The problem here is associated with collinearity among latent variables.
Having said that, in many cases these two types of problems happen together: latent variable collinearity (often referred to as multicollinearity) and poor loadings/cross-loadings.
Happy New Year!
Subscribe to:
Comments (Atom)
