There are several ways in which a model with an endogenous dichotomous variable can be analyzed in PLS-SEM - via the logistic regression variables technique, without any additional treatment, and via the conditional probabilistic queries technique. Below we discuss the first two options.
Logistic regression variables technique
Starting in version 8.0 of WarpPLS, the menu option “Explore logistic regression” allows you to create a logistic regression variable as a new indicator that has both unstandardized and standardized values. Logistic regression is normally used to convert an endogenous variable on a non-ratio scale (e.g., dichotomous) into a variable reflecting probabilities. You need to choose the variable to be converted, which should be an endogenous variable, and its predictors.
The new logistic regression variable is meant to be used as a replacement for the endogenous variable on which it is based. Two algorithms are available: probit and logit. The former is recommended for dichotomous variables; the latter for non-ratio variables where the number of different values (a.k.a. “distinct observations”) is greater than 2 but still significantly smaller than the sample size; e.g., 10 different values over a sample size of 100. The unstandardized values of a logistic regression variable are probabilities; going from 0 to 1.
Since a logistic regression variable can be severely collinear with its predictors, you can set a local full collinearity VIF cap for the logistic regression variable. Predictor-criterion collinearity, or lateral collinearity, is rarely assessed or controlled in classic logistic regression algorithms.
For more on this topic, see the links below.
Explore Logistic Regression in WarpPLS
Using Logistic Regression in PLS-SEM with Composites and Factors
Without any additional treatment
Below is a model with a dichotomous dependent variable - Effe. The variable assumes two values, 0 or 1, to reflect low or high levels of "effectiveness".
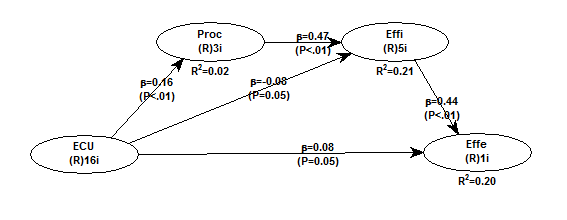
The graph below shows the expected values of Effe given Effi. The latter is one of the LVs that point at Effe in the model. The values of Effe and Effi are unstandardized.

Arguably a model with a dichotomous dependent variable cannot be viably tested with ordinary multiple regression because the dependent variable is not normally distributed (as it assumes only two values).
The graph below shows a histogram with the distribution of values of Effe. This variable's skewness is -0.423 and excess kurtosis is -1.821.

This is not a problem for WarpPLS because P values are calculated via nonparametric techniques that do not assume in their underlying design that any variables in the model meet parametric expectations; such as the expectations of univariate and multivariate unimodality and normality.
If a dependent variable refers to a probability (as in logistic regression), and is expected to be associated with a predictor according to a logistic function, you should use the Warp3 or Warp3 basic inner model algorithms to relate the two variables.



